The Eclipse team has been hard at work for over a year now, so I thought I'd take this opportunity to reflect a bit on how we got here.
For those who have been following Eclipse, you'll know that our focus has zeroed in on building Eclipse Mainnet: Ethereum's fastest L2, powered by the SVM. Its architecture represents the culmination of our learnings from deploying our rollup framework for a variety of applications.
Before I get into where we came from, I want to touch on where we are now. I don't want to oversell where Eclipse is today. We're very much at the beginning of our journey. We still need to launch mainnet, grow an active ecosystem, decentralize our proofs, strengthen bridge contract upgradability, and many other things. That won't happen overnight. We're heads down focused on a successful mainnet launch over the coming months and will continue to build for years after.
Nonetheless, we have made some great progress already. This is what we've learned along the way:
The Dawn of Eclipse
We started talking to app developers a bit over a year ago, offering to spin up customizable rollups using the Solana Virtual Machine (SVM). A rollup-centric roadmap seemed to imply a world with thousands of rollups, so there was a lot of interest. We ended up running 30+ testnet chains alongside the application teams trying them out.
The operational burden was non-trivial. When chains went down at 2AM, our Head of Engineering David would receive the call. When teams had issues with their infrastructure integrations, our core engineers were expected to act as a liaison and intermediate. When apps wanted to launch a native token with the chain, we coordinated with all necessary parties. This workload wasn't scalable or sustainable.
Even for our customers, app-specific rollups weren't optimal. It's more difficult to onboard users, bridge between rollups, compose with apps on the L1, and bootstrap meaningful economic activity. Each additional rollup added complexity and reduced interoperability.
We dove into the myriad proposed solutions. Self-service bridges, shared sequencers, indexers-as-a-service, new "settlement layers" as liquidity hubs. Dozens of companies have been assembled to service the purportedly imminent influx of thousands of app-specific rollups. Trying to solve self-engineered complexity by adding new layers of complexity didn't strike us as convincing. We started to re-evaluate our position toward app-specific rollups.
More Rollups More Problems
What the world truly needs is just one more rollup – especially if it's ours.
Problem 1: App-specific rollups are uneconomical for most applications.
We discovered the open secret that most app-specific rollups have a very high fixed cost. I even gave a talk at the Modular Summit about it: Rollups-as-a-Service Are Going To Zero.
After running 30+ testnet chains ourselves, we quickly realized the magnitude of these fixed costs. Even a bare minimum rollup configuration demands significant expenses, including:
- Sequencer
- Full nodes for the executor, verifier(s), fast finality bridge
- Indexers
- Engineering support
- Posting state commitments and sometimes additional sequencer data to the L1
...before considering additional infrastructure integrations. These expenses are higher for mainnet chains.
Aside from the costs above, app-specific rollup developers face high startup costs from infrastructure partners. Major RaaS providers charge on the order of $60K-$100K+ annually as well as take a percentage of all sequencer fees. Additionally, these teams face the implicit costs of increased developer complexity and user friction.
It's also worth noting that certain popular rollup stacks make the economics for smaller app-chains (which lack very high transaction throughput) even more challenging today. For example, OP Stack chains carry particularly high fixed costs because they routinely post to the L1 regardless of L2 activity. (Note that this specific inefficiency can be changed in the future, and not all stacks have this issue.)
Overall, it's far more economically efficient to reduce overhead, deduplicate work, and amortize these high infrastructure costs across a single shared chain.
Problem 2: The customizations offered by app-specific rollups are largely unnecessary.
This lesson hurt, because customizability was one of the original motivations for Eclipse.
Customizing your own chain sounds nice in theory, but the reality is most apps don't need or want it. These changes are generally far more trouble than they're worth, since they must be audited from both a technical and cryptoeconomic perspective. Each novel customization means increased complexity and potentially worse interoperability. This equally applies to L1 app chains:
"The Cosmos SDK is incredibly generic and yet it never inspired the plethora of diverse chains that you might expect. This could be because customization requires too much technical sophistication, or more likely because the long tail of applications is well-suited by a handful of architectures."
To be fair, it's worth mentioning that there are some cases where we think app chains make sense, but it's not really about customization. These cases are driven by ownership, sovereignty, and the community's ability to control forks and upgrades.
Problem 3: Non-Ethereum settlement layers are a nerd trap.
The original idea for Eclipse was to launch our own settlement layer with the other app-specific Eclipse rollups deployed as "L3s":
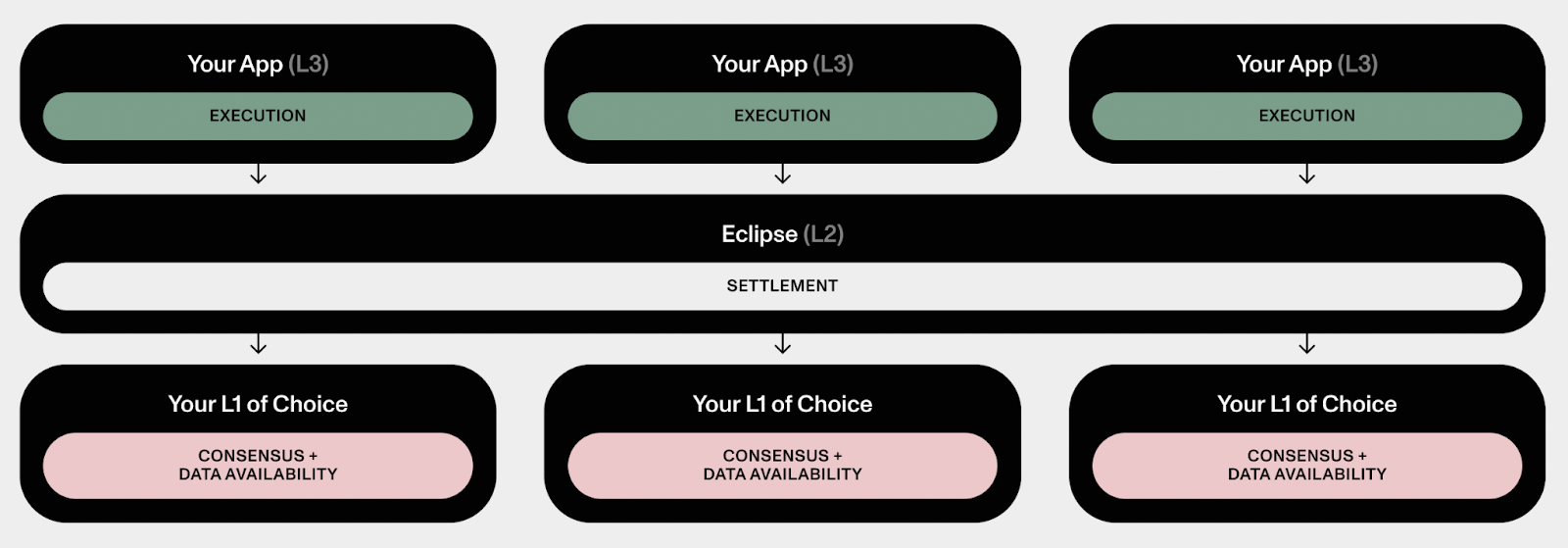
Old and Not-So-Great Eclipse Architecture
We did this primarily because it made the settlement process easier. For a naive implementation of optimistic SVM settlement, a custom settlement layer gave us the optionality to introduce custom precompiles or other operations to facilitate the settlement of our rollups. It also would've been cheaper than using Ethereum as a settlement layer.
But we always wanted to use Ethereum. A good settlement layer has a lot of native liquidity, high security (both safety and liveness), easy verifiability, and credible neutrality. Ethereum checks all boxes. ETH is the lingua franca of crypto: it's how we pay our gas, denominate our trades, and purchase our NFTs. Bitcoin is the only chain that's competitive on those properties, and Bitcoin doesn't have the functionality needed to support enshrined settlement.
Our engineering team made quick progress on our zk-VM, which made zk-fault proofs on Ethereum feasible. And it turns out settlement is pretty cheap, even on Ethereum. An optimistic rollup pays on the order of ~$5 per day to Ethereum. For these reasons, we abandoned our L2 settlement layer, and instead we opted to use Ethereum for settlement.
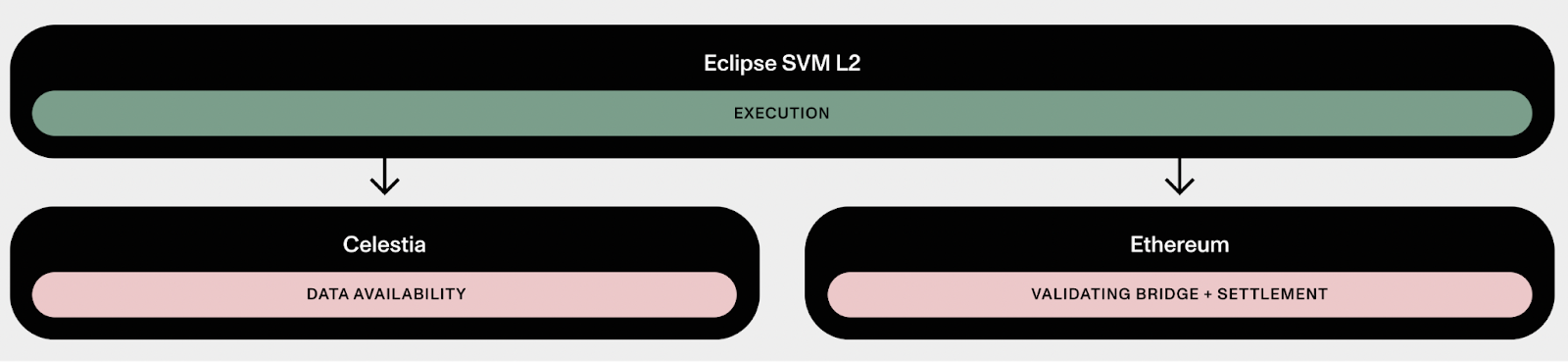
Eclipse Mainnet Architecture
And as mentioned above, it's difficult for a non-Ethereum settlement layer to be economically sustainable, because settlement layers generate very little revenue directly. Settlement transactions are super cheap, especially for optimistic rollups. It's just writing a handful of bytes (a state commitment) to the settlement layer periodically.
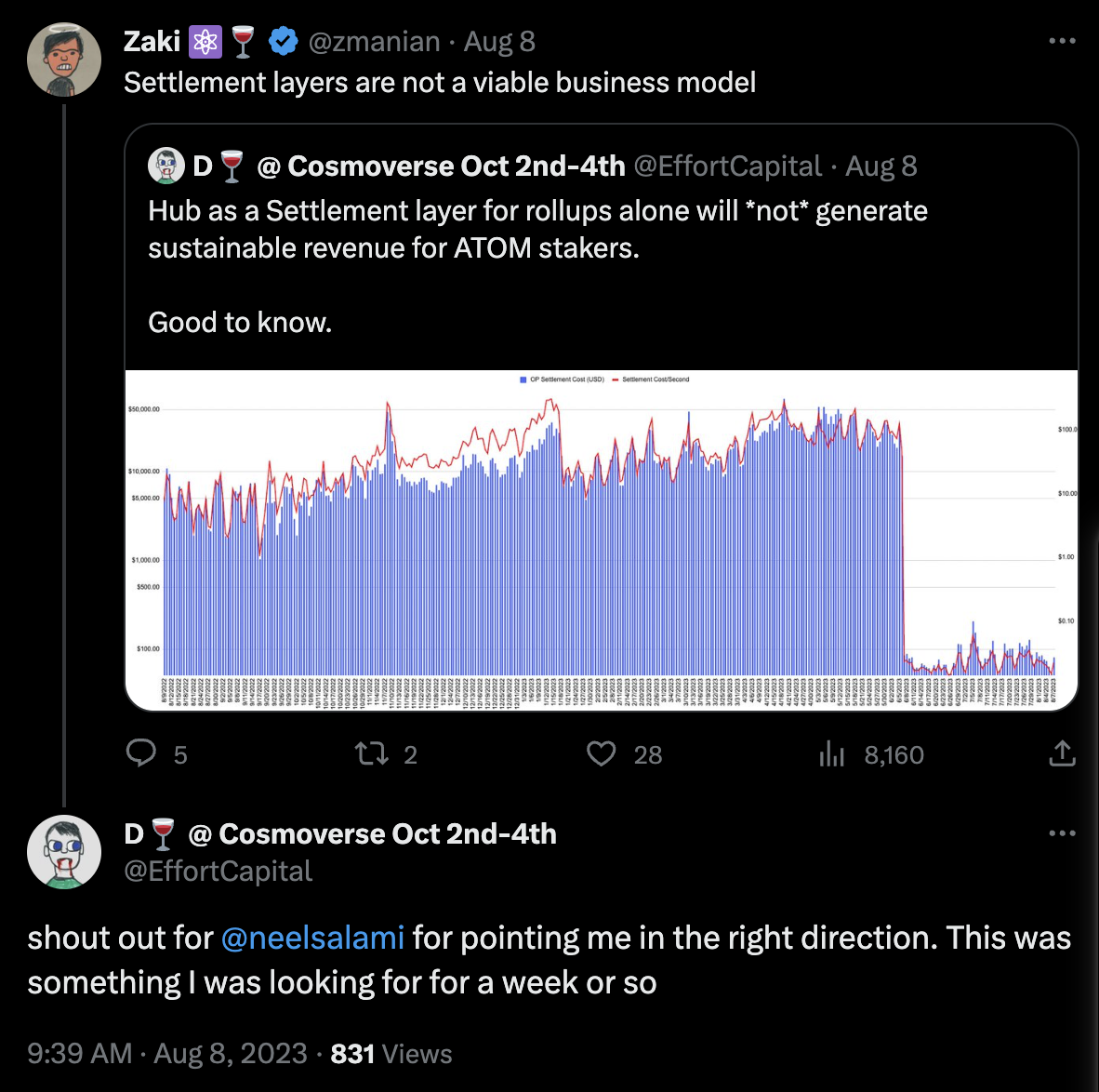
The only way for a settlement layer to be economically sustainable is by indirect value capture. Most importantly, ETH becomes the de facto money everyone holds. (Ethereum also has native L1 transactions which generate gas fees. But I suspect this is not nearly as important for ETH as its "moneyness.")
Trying to build a new settlement layer at this point feels like a complicated and unnecessary form of lock-in. Just use Ethereum.
We Can "Have Our Cake And Eat It Too"
Finally, our learnings from this past year coupled with several technical advancements brought us to the Eclipse Mainnet architecture. A shared general-purpose L2 that addresses the challenges that app developers actually face without sacrificing UX or fragmenting liquidity.
We're excited to build in public and support the cutting-edge apps that developers build, kicking off a new wave of innovation on Ethereum.
